





























































Programming at web scale with data caching
Introduction
Caching is an important aspect of building an application that performs well at web scale. Proper caching can reduce the number of API calls, save on CPU time, make requests faster, the application more responsive, and reduce the infrastructure cost.
We used one of the techniques mentioned in this article to reduce the average response times from upto 200 ms to 3 ms, reduction by a factor of 67.
The concept of caching is pretty simple – store the result of any computation that takes a long time and is accessed more frequently than it changes. In the following blog post, we discuss 3 levels of caching and how it can help speed up an application, followed by some gotchas and solutions to common problems related to caching.
External cache
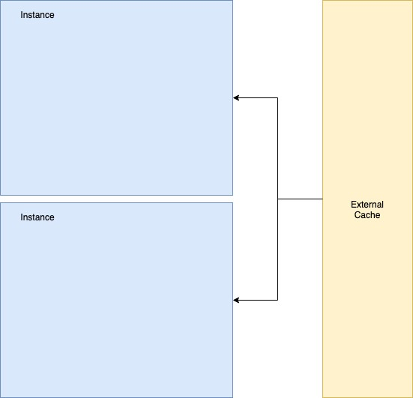
The external cache is stored outside the instance serving web requests and is shared among all the instances serving the application. It is stored in a fast NoSQL lossy database like MemcachedTM or RedisTM. This can be used to speed up API requests or expensive database calls. For example, a friend list or some computed group statistics, etc. When the data is needed, it can be fetched from the cache instead of computing it again.
The access for such cache is typically about single-digit milliseconds compared to 10s or 100s of milliseconds that may be incurred while fetching or computing the data. This level of cache can be used to store user-level information as well. A user may hit any instance in the deployment and end up hitting the precomputed cache. Typically, things that don’t change often but take a long time to construct are stored here.
Instance level cache
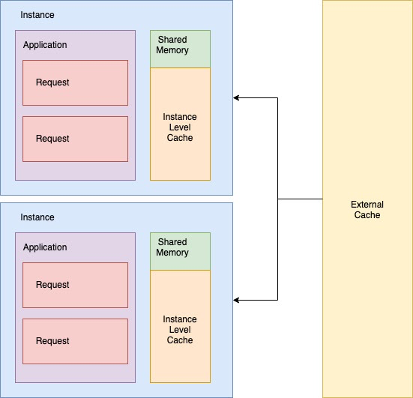
This level of caching can be used for the data that can be stored in a shared memory location of the instance or container serving the request. This can be accomplished by running a local Memcached or Redis on the instance or by using a software that allows accessing shared memory. It can be used for storing things like parsed configuration files – they can be fetched and parsed once when the server starts and kept in memory thereafter to avoid CPU and memory intensive parsing.
This cache is faster than the external cache as it avoids the overhead of the network hop to go to the external cache and stores the information directly in the shared memory of the instance.
The data cached at this level should be the same for all the users. Never cache user data at this level because a user can hit multiple instances on the cluster recreating and saving the cache on each of them. This may cause the memory to run out on instances if there are a substantial number of users.
Request level
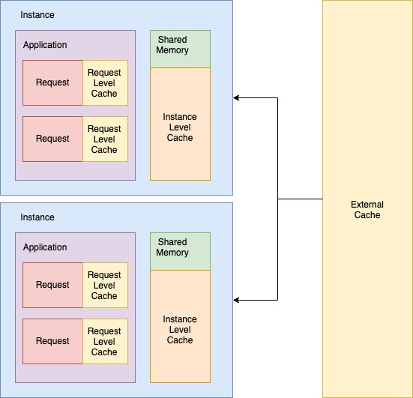
This level of cache is best for data that is accessed multiple times within the same request. Data that needs to be computed over and over or something that is fetched multiple times from a database or API. Such data or computation can be cached at the web request level using variables that get initialized when the request is constructed.
User data that is accessed more than once in a request is a good candidate for this. Such data is not suited for instance level cache because it is not required after the request is complete. But, while the request is in flight, having it cached can save network resources and improve response times.
Accessing shared memory may require copying the contents into a new memory location or the data may be stored serialized in the shared memory. Unserializing it on each access can be expensive. In such cases, storing frequently accessed instance level cache at request level may further improve response times. For example, a loop accessing instance level cache hundreds of times or a configuration value stored in instance level cache accessed multiple times throughout the request.
It is this technique that helped us gain the improvement by a factor of 67 for our response times, noted in the beginning of this post.
Gotchas
Caching does not come for free! If not done correctly, it may become a source of various pain points ranging from bugs to infrastructure management.
Stale cache and cache bursting
The cache can hang around. When a cache is set, it is usually valid for some time. The validity of the cache needs to be thought-about to make sure that the cache is invalidated at all levels once it is refreshed. It is also a good idea to have reasonable timeouts at each level so it is refreshed periodically. These timeouts are referred to as “Time To Live” for the cache or just “TTL”.
Another approach can be to version the key names by including a version in them, changing the version will cause a force refresh. The most prominent examples of this are javascript, CSS, and Image files on the web. They are cached at various levels on the internet – browsers, CDN, intermediate caches and the only way to reliably fetch a new file is to append a version or change the name based on a hash.
Setting reasonable Time To Live (TTL)
Deciding how long a cache will be valid is very important. A TTL that is too long may expose the application to possibility of stale cache, while having too short of a TTL may mean the application is not running as efficiently as it could.
It is also a good idea to get familiar with how the caching software interprets TTL. For example, in Memcached, TTL of 0 means the key never expires, if the TTL is less than 30 days (2592000) it is interpreted as the number of seconds until key expiry. But, if it is greater than 30 days the TTL is treated as a unix timestamp.
Thrashing
When a cache expires, all the in-flight requests may try to refresh it. This can cause a sudden increase in load, API throttling, network traffic bursts, degradation of services, or even outages if the bursts start a snowball effect.
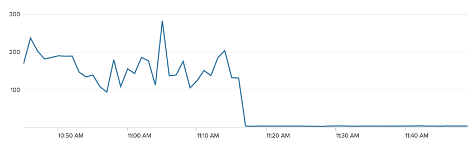
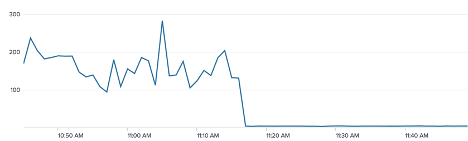
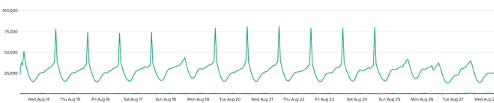
The following image shows the spikes that happened each day when a cache expired. Note the last three days do not have the spike. This problem was addressed by adding a single request cache refresh strategy discussed later in this post. Another way to tackle this problem can be to stagger the cache expiry by picking a random number in a range for TTL of the cache say 3 and 5 minutes to help distribute the refresh calls within different instances.
Hotkey problem
If there are multiple instances in the external cache and there is one key that gets accessed often, it gets hashed to one of the nodes in the external cache. This one node starts getting increased traffic and network i/o. This degrades the performance for all the other keys living on that particular instance of the external cache.
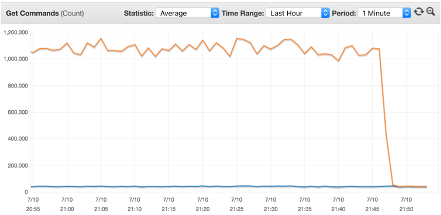
In such a situation, adding an extra level of caching at the instance level for the data that is accessed frequently may have a huge impact. The image below shows the number of “get” commands caused by a single key. Adding an instance-level cache of a few seconds TTL reduced the number of gets by 90%
There can also be a situation where there are multiple hotkeys. There may be a class of keys that are accessed more frequently and may be contributing disproportionately to the network traffic. In such situations, you may want to split your data into different clusters based upon matching read/write access patterns. Group the high read keys together and the low read keys together so that their traffic requirements do not interfere with each other. This solution may not apply to all scenarios, but can help large applications scale.
Single thread refresh strategy
I mentioned this technique in the thrashing section. It can be a very effective way to counter thrashing by reducing the refresh attempts from potentially hundreds or thousands to one per instance. To use this, the data can be stored with two keys instead of one:
- Data key – holds the data
- Lock key – manages the refresh of data
It can be implemented as follows:
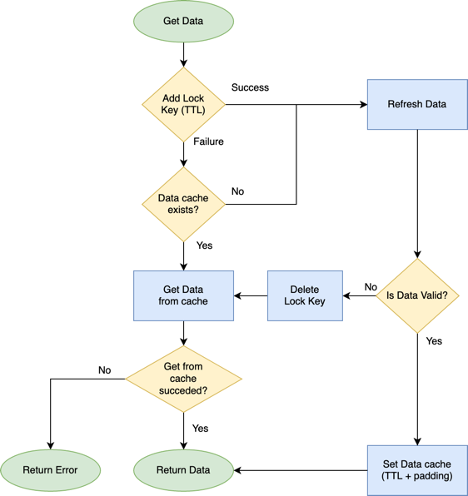
- TTL for data key is padded by a few seconds to be longer than required TTL (TTL + padding)
- Padding should be longer than the time required to refresh data
- TTL for lock key is set to the required TTL
- Each request uses an atomic “Add” operation to add a lock key
- Data is refreshed only if request is able to add the lock key
- Any request that tries to access the key while it is being refreshed, serves the slightly stale data key, which is available due to the extra padding
sample implementation:
function getData () {
key:string = “unique_key”
dataKey:string = key + “_data”;
lockKey:string = key + “_lock”;
if(cache::add(lockKey, ttl)) {
data = computeOrFetchExpensiveData();
//only cache if data is valid
if(isValid(data)) {
cache::set(dataKey, data, ttl+padding);
} else {
//delete lockKey for another request to add and update data
cache::delete(lockKey)
}
}
return cache::get(dataKey);
}
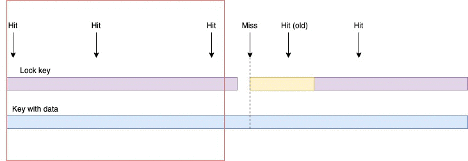
In the following image you can note, with the lock key, the request “Hit (old)” serves the old data without trying to refresh while an earlier request (Miss) refreshes it. “Hit (old)” would have been a miss without such implementation and would have attempted to refresh the data. In the real world, most of the cache refreshes take milliseconds and rarely more than a second so serving stale cache for that duration is acceptable in the majority of cases.
External Cache
Having an external cache creates an additional dependency for the application. Care should be taken that a failure to reach the external cache has an appropriate fall back – like performing the computation in line. Such a design can help avoid an outage in case of failures with the cache.
This cache lives on servers outside the application, which is an additional cost that should be evaluated. Lastly, the external cache has limited memory, if the memory is too little or the TTL is not set right, increased evictions of the cached keys may lead to a loss of cache and degraded performance for users.
Conclusion
Over the past few years here at Zynga, we have been able to leverage these techniques to design scalable backends for our games. We were able to drastically reduce our response times by a factor of 67 using the instance level cache. We were able to eliminate daily thrashing and a burst of 500 errors from our servers using the single thread refresh strategy. We were also able to reduce the cost of external cache in half by identifying a few hot keys and adding an instance level cache in front of it.
While architecting an application, it is a good idea to evaluate what level a particular cache should be put in and what parts of the system can take advantage of one or more of these techniques to make high performing web-scale applications providing a world-class experience to your users.
Zynga is a registered trademark of Zynga in the U.S. and other countries. All trademarks not owned by Zynga that appear in this article are the property of their respective owners and this is an independent article and is not affiliated with, nor has it been authorized, sponsored, or otherwise approved by the respective owners. Redis is a trademark of Redis Labs, Ltd. Memcached is a trademark of Danga Interactive, Inc. Splunk is a trademark of Splunk Inc. AWS CloudWatch is a trademark of Amazon Web Services, Inc.
©2020 ZYNGA INC.